
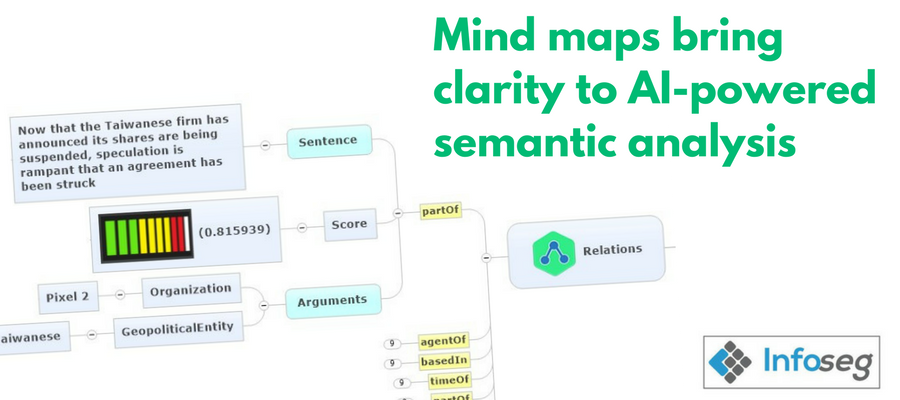
Mind maps are powerful tools for gathering and organizing large amounts of information and knowledge. But they can also be used to output structured data from a variety of sources. When I last talked to Jose Guerrero, the managing director of InfoSeg S.A. in 2013, his team had created a tool that worked with MindManager to import your LinkedIn data in a variety of formats. What he’s doing now is another order of magnitude more amazing: Using IBM’s Watson Natural Language Understanding (NLU) AI engine to semantically analyze large amount of text and parse it into a mind map, with 8 areas of reporting.
I recently interviewed Jose about this exciting, cutting-edge project and why mind maps are still his preferred format for outputting data from this powerful cloud-based tool:
Chuck Frey: How is this an extension of the past work you did with mind mapping – such as parsing LinkedIn profiles and making mind maps out of them?
 Jose Guerrero: Only the idea of visualizing complex information as mind maps is similar. In this case, IBM Watson™ NLU processes text and web pages and generates a full semantic analysis of categories, concepts, emotion, entities, keywords, metadata, relations, semantic roles and sentiment. The result of this semantic analysis is a series of lists containing very complex information. It would be very difficult to understand these results if the user receives them as linear text or web pages. It would be almost impossible to see the “whole picture”. Mind mapping helps the user to see the “whole picture” and work on the results in an efficient way.
Jose Guerrero: Only the idea of visualizing complex information as mind maps is similar. In this case, IBM Watson™ NLU processes text and web pages and generates a full semantic analysis of categories, concepts, emotion, entities, keywords, metadata, relations, semantic roles and sentiment. The result of this semantic analysis is a series of lists containing very complex information. It would be very difficult to understand these results if the user receives them as linear text or web pages. It would be almost impossible to see the “whole picture”. Mind mapping helps the user to see the “whole picture” and work on the results in an efficient way.
Frey: Why did you select IBM Watson versus another AI platform?
Guererro: I selected IBM Watson™ NLU because it is a very solid and well tested solution, IBM is going to use it in the long term, IBM is going to improve it and there is no danger that they change it for something different in the near future.
A further reason is that developers can adapt IBM Watson NLU to specific environments like healthcare, insurance, banking, marketing, engineering and others by using custom models created with Watson Knowledge Studio. Watson, as a cognitive system, has some capabilities that are not found in traditional programmed computing systems, including:
- It understands like humans do, processing natural language and other unstructured data.
- It learns, getting more valuable with time.
- It reasons. It understands underlying ideas and concepts, form hypothesis, infers and extracts concepts.
- It interacts. It has abilities to see, talk and hear. It can interact with humans in a natural way.
Natural Language Understanding uses natural language processing to analyze semantic features of any text in the form of plain text, HTML, or a public URL.
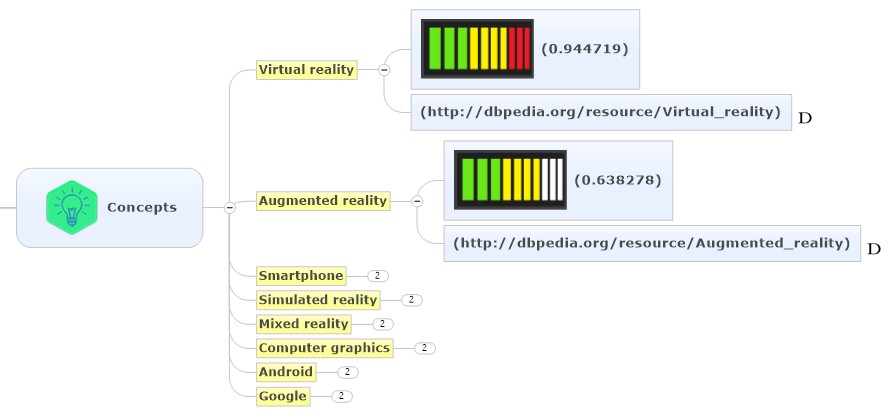
Frey: What is Natural Language Understanding (NLU) and how does that work?
Guerrero: The main features of IBM Watson NLU are:
- Uncover insights from structured and unstructured data. Analyze text to extract meta-data from content such as concepts, entities, keywords, categories, relations and semantic roles.
- Understand sentiment and emotion. It returns both overall sentiment and emotion for a document, and targeted sentiment and emotion
towards keywords in the text for deeper analysis. - NLU understands text in nine languages, including English, Spanish, French, German, Russian, Italian and Arabic.
Frey: How do you foresee a business executive using NLU-MAP? What are the use cases?
Guerrero: The sources of text to analyze are:
- Social media and blogs
- Articles
- Research reports
- Enterprise mail and e-mail
- Surveys
- Documents
- Voice transcriptions
- Chat
- News
- Knowledge bases
The most important types of use are:
- Social media monitoring
- Content recommendation
- Opinion mining
- Content profiling
- Add placement
- Buyer intent analysis
- Churn prevention
- Financial prediction
- Brand and product intelligence
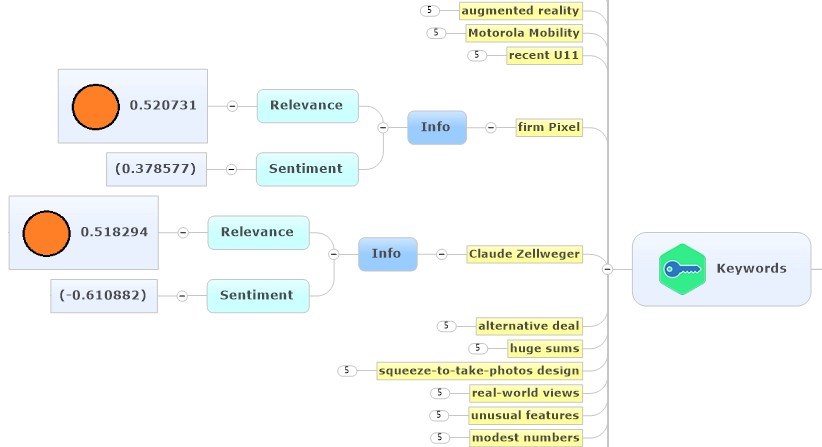
Frey: The IBM Watson web page describes NLU as being able to work with both structured and unstructured data. Why is that significant?
Guerrero: Most of the information we have nowadays (80%) is unstructured. In the future, in fields like healthcare, insurance and banking, this is going to be our main problem.
Frey: What’s next for NLU-MAP?
Guerrero: I would like to work in a version of this program to analyze technical papers in healthcare, insurance, banking, engineering, etc. so that the productivity of experts could be improved substantially. For example clinical or research teams of physicians have to read thousands of academic papers every year. They suffer from information overload.
The possibility of improving their productivity by 30 or 40% would be an enormous achievement.
This will be all as far as NLU-MAP is concerned. However, we have plans for other developments related to the IBM Watson™ environment:
- Tone Analyzer. This will be an add-in for Outlook so that users can see the tone of the messages they are going to send. In this way users will be confident that their messages do not contain improper content.
- Chatbots. Create a summary of conversations that can be analyzed later.
- Personality insights. Obtain a psychological portrait of a person as a mind map.
- Discovery. Visualize the result of searches in collections of documents.
Frey: You told me in an email that short texts work best for now. When will it be able to handle longer texts?
Guerrero: Well, you can work with very long texts right now. The only problem was that without mind mapping the amount of information generated by IBM Watson NLU was enormous and very difficult to analyze. Now, our product NLU-MAP is going to make this less of a problem. However the idea is not to use NLU-MAP for very long texts like books, for example.
Click here to view Jose Guerrero’s presentation about NLU-MAPs on Slideshare

Leave a Reply